Optional parameters in a stored procedure often lead to scans in the execution plan, reading through the entire table, even if it’s obvious that the right index is in place. This is extremely common in procs that are used behind search screens where, for example, you could search for a person according to their first name, last name, city, state, zip code, gender, etc.
To take a simplified look at this, make a quick and easy table consisting of an indexed identity column for us to search by and fluff to make the row size bigger.
CREATE TABLE Test ( ID Int NOT NULL Identity(1,1) PRIMARY KEY , Value CHAR(500) NOT NULL ) GO INSERT INTO Test (Value) SELECT ''; GO 250 INSERT INTO Test (Value) SELECT TOP (1000) Value FROM Test GO 100
Now we’ll create a proc to get data. In this proc we’ll get the data several different ways, showing the advantages and disadvantages of each method. You’ll notice that I put my comments as PRINT statements, which will make it easier for you to read through the messages tab and see what’s going on.
CREATE PROC proc_Testing @ID int = 125 , @MinID int = 100 , @MaxID int = 150 AS SET STATISTICS IO ON SET NOCOUNT ON PRINT 'Clustered index scan, because the query optimizer has to be prepared for both null and non-null values' SELECT * FROM Test WHERE @ID = Test.ID OR @ID IS NULL PRINT '' PRINT 'It''s a small mess, but the query optimizer knows exactly what to expect for each query.' IF @ID IS NOT NULL BEGIN SELECT * FROM Test WHERE @ID = Test.ID END ELSE BEGIN SELECT * FROM Test END PRINT '' PRINT 'Expand that to two possible parameters and it still looks simple right now, when it''s doing a scan' SELECT * FROM Test WHERE (ID >= @MinID OR @MinID IS NULL) AND (ID <= @MaxID OR @MaxID IS NULL) PRINT '' PRINT 'Make it optimized with IF statements and it quickly becomes a big mess.' PRINT 'Many "search screen" queries will have 20 or more optional parameters, making this unreasonable' IF @MinID IS NOT NULL BEGIN IF @MaxID IS NOT NULL BEGIN SELECT * FROM Test WHERE ID BETWEEN @MinID and @MaxID END ELSE BEGIN SELECT * FROM Test WHERE ID >= @MinID END END ELSE BEGIN IF @MaxID IS NOT NULL BEGIN SELECT * FROM Test WHERE ID <= @MaxID END ELSE BEGIN SELECT * FROM Test END END PRINT '' PRINT 'However, the query optimizer can get around that if it''s making a one-time use plan' SELECT * FROM Test WHERE (ID >= @MinID OR @MinID IS NULL) AND (ID <= @MaxID OR @MaxID IS NULL) OPTION (RECOMPILE) PRINT '' PRINT 'And again with the single parameter' SELECT * FROM Test WHERE ID = @ID OR @ID IS NULL OPTION (RECOMPILE) PRINT '' PRINT 'However, this leaves two nasty side effects.' PRINT 'First, you create a new plan each time, using CPU to do so. Practically unnoticed in this example, but it could be in the real world.' PRINT 'Second, you don''t have stats in your cache saying how indexes are used or what your most expensive queries are.' PRINT '' PRINT 'Another option is dynamic SQL, which still has most of the first flaw, and can also bloat the cache' DECLARE @Cmd NVarChar(4000) SELECT @Cmd = 'SELECT * FROM Test WHERE 1=1' IF @ID IS NOT NULL BEGIN SELECT @Cmd = @Cmd + ' AND ID = ' + CAST(@ID AS VarChar(100)) END IF @MinID IS NOT NULL BEGIN SELECT @Cmd = @Cmd + ' AND ID >= ' + CAST(@MinID AS VarChar(100)) END IF @MaxID IS NOT NULL BEGIN SELECT @Cmd = @Cmd + ' AND ID <= ' + CAST(@MaxID AS VarChar(100)) END EXEC (@Cmd) PRINT '' PRINT 'Yes, you can do sp_executesql which can be parameterized, but it gets more difficult.'
Now that we have the data and proc, just execute it. It will be best if you add the actual execution plans to this, which you can get to on your menu going to Query / Include Actual Execution Plan. If you don’t know how to read execution plans then this is even better! No experience necessary with plans this simple, and you’ll start to feel more comfortable around them.
EXEC Proc_Testing
Even with the default values for the parameters the query optimizer knows that you could have easily passed in NULL for the values, and it has to plan for everything. Lets step through the results to see what this all means. Part of that planning for everything is saying that @ID IS NULL will be used instead of ID = @ID, so the query optimizer can’t say for sure that it can just perform a seek on that column.
In the messages tab we have the number of reads done by each statement courtesy of me adding SET STATISTICS IO ON in the proc itself (bad idea in prod, by the way). For the first one we have 7272 logical reads, saying we read 7272 pages of 8kb of data, so we had ask the CPU to play around with over 56 MB of data to find records that matched.
Looking at the execution plan we can see why that happened. The Predicate you can think about as the “Scan Predicate”, since it’s saying what you couldn’t seek for and had to scan instead. In this case it’s showing the entire “@ID = Test.ID OR @ID IS NULL” in there, because it compiled a reusable plan that might be used with a NULL.
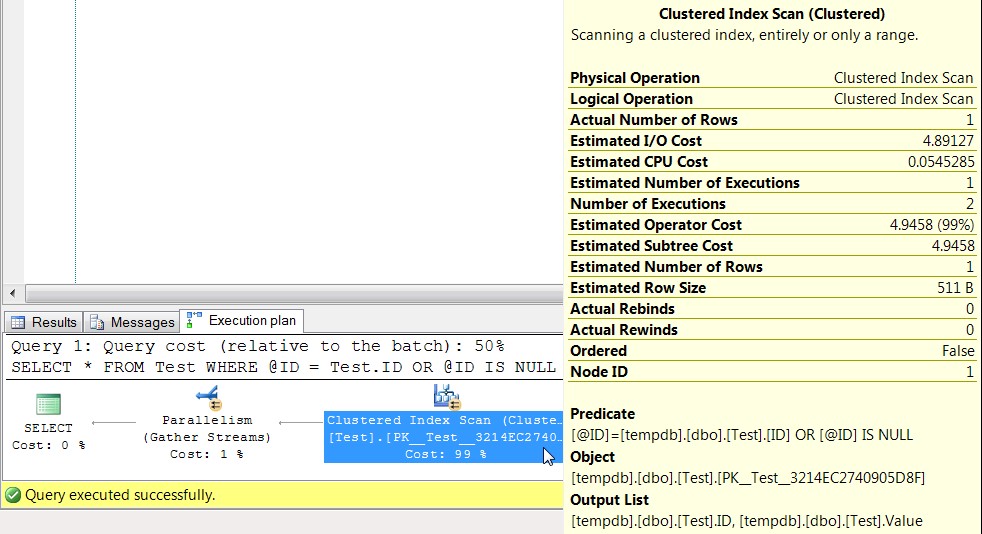
In the next statement we were able to do a seek, doing only 3 reads. This is because there are two levels of the B+tree on this index, so it read the root level, then the next level of the B+tree, and finally the single leaf level of the index that contained the data we wanted.
Take a look at the execution plan here to see the difference with not only the Seek itself, but the Seek Predicate in the details. You’ll see that it uses @ID in there still showing that it’s a reusable plan ready for any ID to be passed in, but the WHERE clause is telling the query optimizer that it can always use a seek to find this data.

Now that I know you can read through a couple yourself, I’ll skip ahead to the 6th query where we used the same “@ID = Test.ID OR @ID IS NULL” that caused is trouble before, but did OPTION (RECOMPILE) at the end of the statement. Again it did the same 3 reads I just mentioned still using a seek, but the details of the execution plan looks different. The seek predicate used to say @ID so it could be reused, but the query optimizer knows nothing with OPTION (RECOMPILE) will get reused. Knowing that, it simply converted @ID into a constant value of 125 and was able to eliminate the possibility of 125 being NULL.

If you want to get more into the details, you can look at the XML version of the execution plan by right-clicking on the plan and selecting “Show Execution Plan XML…”. Here’s what you’ll find for the parameter’s value in the first two queries. It shows that the value that was sniffed when it was compiled was 125, and also that it was run this time with a value of 125. If you ran this again passing 130 in then you’d see the sniffed value staying at 125 because it’s not going to use CPU resources to recompile it, but the runtime value will be 130 for that run.
<ParameterList> <ColumnReference Column="@ID" ParameterCompiledValue="(125)" ParameterRuntimeValue="(125)" /> </ParameterList>
The OPTION(RECOMPILE) versions don’t look like this though, they’re changed to a constant value even at this level.
<RangeColumns> <ColumnReference Database="[tempdb]" Schema="[dbo]" Table="[Test]" Column="ID" /> </RangeColumns> <RangeExpressions> <ScalarOperator ScalarString="(125)"> <Const ConstValue="(125)" /> </ScalarOperator> </RangeExpressions>
I hope I left you with a better understanding of what happens when you write code for parameters that could be null. We’ve all done this, and many of us (me especially) have been frustrated with the performance. This is a change I put into production not too long ago that ended scans on a rather large table, and the results were noticed in query execution time, the page life expectancy counter since the entire table was no longer being read into memory, and I/O activity levels since that index and the indexes it kicked out of memory didn’t have to be read off of disk nearly as often.
Let me know what you think, and especially if you have a better way of handling this issue.

Pingback: Speeding up a stored procedure