Recompiles can be a hidden bottleneck on your server, and it may not be too obvious. I should know, it happened to me. Unfortunately for me, that was before I was a proponent of tracing or using XEvents to watch for recompiles. Fortunately for you, the experience changed me, and I enjoy sharing my experiences.
What happened to me was a proc that was called WAY too often was taking too long cumulatively. I knew the true root cause of my issue was in the application which was calling the proc once per row, often for about hundred rows, when loading a pretty important page on a web application. However, I just found out the service desk has been getting complaints for a while, and asking the development team to help me rewrite how the page works ended in an answer that didn’t even sound like now. Well, I guess “no” does kinda sound like “now”…
The proc was pretty simple, taking on average about 0.150 seconds to run. Sounds great until you remember that it’s being called about a hundred times for a page load on a web application. 100 * 0.15 = 15 seconds for the page to load, not counting anything else running. Users were threatening to not be users anymore even though they were happy with most other aspects.
I got into it, reworded the query a little, created a perfect index for it, and it got it down to 0.100 seconds to run. This was a large concession on my part because I HATE perfect indexes for a single query, and feel strongly that indexes should focus more on being reusable by many queries. However, even that only got the web page to load in 10 seconds.
Traces of the proc confused me. The statements were running in 0.010 seconds, and there was a 0.090 second gap between runs. That gap was 9 of my 10 seconds. At 10 seconds users avoid a website, but at 1 second users have to be prompted to say it’s not as fast as they’d like.
It took me longer than I’d like to admit to figure out that every run was kicking off a recompile that took 0.090 seconds. This is the point where I started tracing for the recompile reason, and found out it was because statistics were being updated. However, there were no stats in my database that were updated in the last 15 minutes, so I would have never guessed this was the reason without tracing on this event.
This proc loaded data into a temp table, then did some processing on that temp table, and I figured out that there were enough rows being loaded into the temp table to update the stats on it. Removing the temp table was a disaster, it raised my execution time by 0.010 seconds. Yeah, “disaster” can be relative…
Then I came up with a very odd solution that I’ve never seen or heard of before that point, and I haven’t used much since that point. The temp table was swapped out for a table variable. No stats to be updated, so no recompile. Although it assumed there would only be one record in the table variable (it always does), the execution plan was the same. The only difference was the total 0.100 second duration was dropped to 0.010 after losing the 0.090 recompile.
User experience was now a web page that loaded up in just over 1 second, with most of it still being this query. There wasn’t anything more I could do except wait until the page could be rewritten by development where I could rewrite it to get all the results at once. That process took time, and customers were not impatiently watching to see when it would happen.
I wrote this talking about the users, and users care about duration. However, that’s not the whole story. The 0.090 recompile was pure CPU time, it happening 100 times per page call added up to 9 seconds of pure CPU time, and the users having to use this page hundreds of times a day added up to a noticeable impact on the server performance when it went away. Now I admit that the users only used this when they HAD to instead of when they should have, so it was balanced out a little by the users opening the page about twice as often. Even then, it was still obvious that it was gone when comparing long-term CPU usage.
The Management Response
Side note for all of you managers out there… My manager pulled me aside the next week saying “step into my office for a second.”. I admit, that statement always makes you nervous, even when you KNOW everything is going great. He proceeded to tell me that before I started with the company they pulled developers and a DBA into a task force that spent tons of money to improve performance, upgrading servers, upgrading the SAN, upping the WAN speed, and looking into the database. Then he said that I did more in one day than they did in 6 months without spending any money, and that I should take my wife out for a nice dinner and bring him the receipt.
Now I know that the hardware upgrades helped out, that I only helped a single process that day, and many other things that could belittle what happened. I also know that spending $100 was very minor in terms of the effect that change made for the company. That’s not how I saw things.
What I saw was a response that stuck with me, a lot. Management stepped back to recognize a difference someone made, and made sure they knew they were appreciated. Then took it a step further bringing the family into it, having my wife feeling proud and appreciated at the same time.
I know the constraints management is under and all the things they can’t do. That being said, the only thing that frustrates me about this situation is that I don’t see others in management taking the same approach. I swore from that point that if I ever became a manager my one odd request would be that I would want a very small budget in writing to use at my digression. Small things to show appreciation go a long way.
My Challenge
The challenging part for me, and where I felt I didn’t do as well as I should have done, is that this flew under my radar. I was tracing for anything that took over 1 second duration and was looking at the most expensive queries all the time. However, this one took 0.150 seconds and never accumulated time in the plan cache due to the recompiles.
Here’s the thing, I pride myself on being specialized in database performance, so I feel I should have seen this before having someone in customer service casually mention it to me in conversation. It wasn’t even a request to look into it, just mentioning he just got off a call with the customer about the page, and that the page never worked right with no one being able to fix it.
After finding and resolving the root cause of the proc, I also wanted to find and resolve how this flew under my radar. This came up to two primary responses. First, the page was taking too long as a whole, so I requested stats on a per-page basis – how long it took to load each time and how long cumulatively. Second, I started watching for recompiles from time to time. Either one of these would have led me to this issue well before that point.
This post is not about monitoring performance on a website, so, although it’s a very important thing to do, I won’t be mentioning that part again.
Monitoring Recompiles
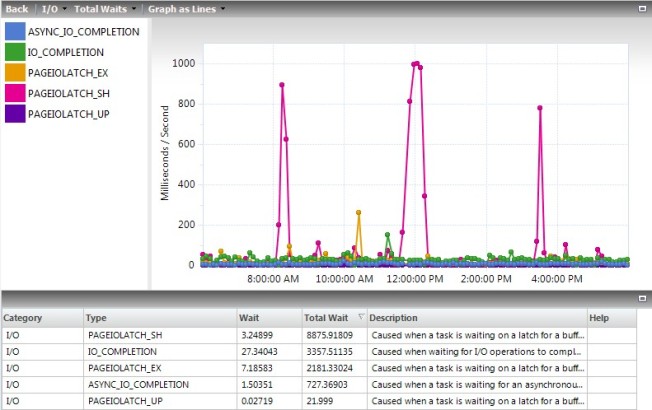
This post is about recompiles, how they can drag you down, and how you can find out about them. I covered how they drug me down, and in past posts I casually mentioned you should use server-side traces or XEvents to monitor them. Then I left it up to you to figure out how. Lets try a different approach today.
Recompiles aren’t something I’m watching for constantly, so I’m not going to run any kind of monitoring constantly for them. What I’ll do is run an XEvent session for 24 hours and analyze what it picked up. If it didn’t recompile often that day it almost definitely does not belong on my priority list, so this works for me.
Here’s my session. It starts immediately, writes to five 10MB rollover files, and will not start the next time your services restart.
IF EXISTS (SELECT 1 FROM sys.server_event_sessions WHERE name = 'Recompiles') DROP EVENT SESSION [Recompiles] ON SERVER; GO CREATE EVENT SESSION [Recompiles] ON SERVER ADD EVENT sqlserver.sql_statement_recompile ( SET collect_object_name=(1) , collect_statement=(1) ACTION (sqlserver.database_id , sqlserver.database_name , sqlserver.session_id , sqlserver.sql_text , sqlserver.username)) ADD TARGET package0.event_file (SET filename=N'Recompiles' , max_file_size=(10) ) WITH (MAX_MEMORY=4096 KB , EVENT_RETENTION_MODE=ALLOW_MULTIPLE_EVENT_LOSS , MAX_DISPATCH_LATENCY=30 SECONDS , MAX_EVENT_SIZE=0 KB , MEMORY_PARTITION_MODE=NONE , TRACK_CAUSALITY=OFF , STARTUP_STATE=OFF) GO ALTER EVENT SESSION Recompiles ON SERVER STATE = START;
Querying the Recompiles XEvent Session
Then I’ll use this query to look at my session. It’s a little awkward in two ways.
First, I only leave the session running for a day, but this script needs it to be running to read from it. The only reason for that is it pulls the file path from the running sessions. You can get around this by putting the path into the script manually. As for me, I usually query it and figure out my next steps while it’s running, then I stop the session.
Second, and this is quite humorous to me, it recompiles due to my temp tables every time it runs. It’s a great example of what to ignore because it’s a low-cost recompile that happens on a seldom-used ad-hoc query where performance is not a major priority. However, because temp table definitions are cached for proc plans, this goes away if you turn this script into a proc. I laugh every time…
When you get the results in the #Queries temp table in the end they’re what you’re used to with it just being a table and all the XML out of the way. The query at the end of the script views them all, but I’ll play around with it doing aggregations and more. I encourage you to do the same. This is also why it drops the table if it exists in the beginning instead of dropping them at the end.
DECLARE @SessionName SysName , @TopCount Int = 1000 SELECT @SessionName = 'Recompile' --SELECT @SessionName = 'system_health' /* SELECT * FROM sys.traces SELECT Session_Name = s.name, s.blocked_event_fire_time, s.dropped_buffer_count, s.dropped_event_count, s.pending_buffers FROM sys.dm_xe_session_targets t INNER JOIN sys.dm_xe_sessions s ON s.address = t.event_session_address WHERE target_name = 'event_file' --*/ IF OBJECT_ID('tempdb..#Events') IS NOT NULL BEGIN DROP TABLE #Events END IF OBJECT_ID('tempdb..#Queries') IS NOT NULL BEGIN DROP TABLE #Queries END DECLARE @Target_File NVarChar(1000) , @Target_Dir NVarChar(1000) , @Target_File_WildCard NVarChar(1000) SELECT @Target_File = CAST(t.target_data as XML).value('EventFileTarget[1]/File[1]/@name', 'NVARCHAR(256)') FROM sys.dm_xe_session_targets t INNER JOIN sys.dm_xe_sessions s ON s.address = t.event_session_address WHERE s.name = @SessionName AND t.target_name = 'event_file' SELECT @Target_Dir = LEFT(@Target_File, Len(@Target_File) - CHARINDEX('\', REVERSE(@Target_File))) SELECT @Target_File_WildCard = @Target_Dir + '\' + @SessionName + '_*.xel' --SELECT @Target_File_WildCard CREATE TABLE #Events ( event_data_XML XML ) INSERT INTO #Events SELECT TOP (@TopCount) CAST(event_data AS XML) AS event_data_XML FROM sys.fn_xe_file_target_read_file(@Target_File_WildCard, null, null, null) AS F ORDER BY File_name DESC , file_offset DESC SELECT EventType = event_data_XML.value('(event/@name)[1]', 'varchar(50)') , ObjectName = event_data_XML.value ('(/event/data [@name=''object_name'']/value)[1]', 'sysname') , ObjectType = event_data_XML.value ('(/event/data [@name=''object_type'']/text)[1]', 'sysname') , UserName = event_data_XML.value ('(/event/action [@name=''username'']/value)[1]', 'sysname') , Statement_Text = ISNULL(ISNULL(event_data_XML.value ('(/event/data [@name=''statement'']/value)[1]', 'NVARCHAR(4000)'), event_data_XML.value ('(/event/data [@name=''batch_text'' ]/value)[1]', 'NVARCHAR(4000)')), event_data_XML.value ('(/event/data[@name=''wait_type'']/text)[1]', 'NVARCHAR(60)')) , Recompile_Cause = event_data_XML.value ('(/event/data [@name=''recompile_cause'']/text)[1]', 'sysname') , TimeStamp = DateAdd(Hour, DateDiff(Hour, GetUTCDate(), GetDate()) , CAST(event_data_XML.value('(event/@timestamp)[1]', 'varchar(50)') as DateTime2)) , SPID = event_data_XML.value ('(/event/action [@name=''session_id'']/value)[1]', 'BIGINT') , Database_Name = DB_Name(event_data_XML.value ('(/event/action [@name=''database_id'']/value)[1]', 'BIGINT')) , EventDetails = event_data_XML INTO #Queries FROM #Events SELECT q.EventType , q.ObjectType , q.ObjectName , q.Statement_Text , q.Recompile_Cause , q.TimeStamp , q.SPID , q.UserName , q.Database_Name , q.EventDetails FROM #Queries q ORDER BY TimeStamp DESC
Hope It Helps
Let me know how this helps. If anything can be done to make my approach or my scripts better, I’m always open to improvement.