Here’s my full presentation for SQL Saturday #250 in Pittsburgh this past Saturday along with some notes on what I got out of it.
My Lessons
I learned a lot doing this, and I hope people learned a lot from it. For the people on the other side of the podium from me, the main lessons were in what I put in the abstract; they learned mostly about SQL Server. On my side of the podium though, the lessons were far from the same. Public speaking, creating presentation, prepping for unknown audiences, and seeing the gratitude of the SQL Server community in person. Anything that was on the abstract I learned slightly better, but that didn’t compare to what wasn’t on it.
Public speaking was always a fear of mine, and I tend to be someone who avoids my fears. However, throwing myself out there at the public as a whole was never my thing either, and I’ve been doing half decent, at least in my own mind. That being said, I decided to go all out and push myself a little further. After all, what are the chances of them picking me to present with all those professional teachers, consultants, and MVPs out there throwing up their abstracts. Best case I could say I tried, worst case I was going to throw myself out of my comfort zone and hope for the best.
They picked me, which I didn’t let myself expect. Everyone that knew I put in my abstract was also told by me that I only had a 50/50 chance at best, which was more optimistic than I really was, but I don’t like people knowing when I’m being dismissive of myself. It turns I was wrong a lot, and in every case I was wrong I was glad I was wrong.
Being Forced to Get Better
I’m not one to learn things for the sake of learning them, which is why I sucked in school. To really learn things I need a real-life use case, somewhere I’m going to apply it. I didn’t practice speaking ever before because I didn’t speak in front of large groups. I didn’t know how to put together a presentation properly because that’s not my thing…well, wasn’t is probably a better word now. Just like a couple months ago I wasn’t quite sure how to blog, but I’ve made it past that point.
Like everything in my life, blogging went from unknown to addiction quick. I’m not sure that I can say the same thing about speaking, but I can see the possibility. SQL Saturday only comes to Pittsburgh once a year and the local user group, which I’ll be joining soon, only meets once a month and has a single speaker. However, I can’t say that I didn’t look up when the SQL Saturdays in Cleveland and Washington DC were. Also, I took my own thoughts on my presentation and the feedback I received in and immediately starting thinking about how I could make that presentation better.
What’s below is the original, not touched up at all in the last 4 days. In part to show where I went wrong and how I’m going to fix it, and in part because Monday was my first day at a new job. By the way, starting a new job when between jobs is the best and worst thing you could ever do to yourself. You don’t have time to be too nervous about anything because you’re too overworked, but you’re also too overworked. Eh, you can’t win them all.
Well, on to the presentation. What you have here is my script that I talked through and taught myself before the presentation. However, if you were there, you’ll notice this isn’t exactly what I said. I didn’t read it, I presented it. There were no demos (the biggest complaint from the crowd) to avoid me from stumping myself, and the PowerPoint was just a whimsical picture for the start of each paragraph to keep me on track because I knew I’d be nervous and lose my way without a paragraph-by-paragraph guide helping me along.
I must have done at least descent because my reviews came back with two 3’s and the rest 4’s and 5’s out of 5. You’re just asking me to get off topic and start talking about why I hate ratings that are odd numbers, but no, I’m not getting off topic, I’m getting on to my presentation!!!
The Presentation
Download slide deck here.
I’ve been working on databases for over a decade, and most of that without having good standards or monitoring in place. My job was rough and I was much less effective. Now I know what I’m doing and I want to share that knowledge. In this presentation I am going to tell you what I watch and why I watch it. A presentation is a poor format to go through how to do this; having it in writing is much more beneficial to you. That is why I’m pretty much skipping that portion here and diverting you to my blog at SimpleSQLServer.com. Not so much to promote a blog that I lose money on, but instead to give you the resources in the best format.
As a DBA you will hit problems with the performance of your databases. It doesn’t matter if it’s one process or across the board, or if it’s just today or it has always been that way. No matter what it is, the more you know about your servers the easier it’s going to be to fix them.
It’s not easy, there’s no single spot to watch, no single solution to all of your problems, and there’s no “normal” values for these counters you can apply across every server you manage (Note: Thank you, Mike John, you stressed this point a lot). I watch several things on all the important servers, and most of these on every server. The important part is that you watch them continuously, even when you aren’t expecting to use the data. Some parts are cumulative and you can’t tell what was during an incident or what was from overnight maintenance. Other parts are snapshots and there’s no looking back.
(Note: Now I’m on to the stuff Brian Castle taught me. He’s the best you could hope for in a manager, and last I checked he was still hiring at EDMC in Robinson Township near Pittsburgh, PA)
To me, monitoring and baselining is the same thing. I know others will do a specific baselining process on a specific day and keep that. I feel you lose too much doing that and I watch enough to say that I have a continuous baseline going back for 13 months in most instances. I’m not all that worked up about lucky numbers or anything, it’s just nice to be able to say “that annual process we ran last week ran like this last year”. If you’re superstitious or have OCD, 400 days makes me just as happy.
Traces – Snapshot
Wait Stats – Cumulative – Resets on restart
Blocking – Snapshot
Query Stats – Cumulative – Resets on recompile
Index Stats – Cumulative – Resets on restart
OS Perf Counters – Varies
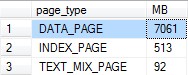
Database Sizes – Snapshot
Table Sizes – Snapshot
Traces – What long running processes have completed on the server?
You have to be careful, this one can kill your server. I have, on more than one occasion (sorry, Brian), caused a large server to reboot in the middle of the day because I filled the drives writing 40 GB of traces in 5 minutes. That being said, there is a safer way to trace, just don’t do an unfiltered trace catching everything.
I personally feel that absolutely every server should have a trace capturing RPC:Completed and SQL Batch:Completed that ran over X seconds duration. What is X? Well, that depends on the server. I’ve seen the best number for X be as low as 100 ms and as high as 10 seconds. Start high, and work your way down. You can add or do a separate trace for the Statement Completed for each of these if you want more detail.
You can get all of this except for SQL Batch:Completed with the text data from Extended Events, and that is a very good alternative. I haven’t made that jump for several reasons, although I would recommend it. First, this level of tracing hasn’t hurt me. Second, I still support several important servers that are still on SQL 2005 and I want to be as consistent as possible to provide as consistent as possible support.
What you’re trying to solve here is answering what ran long, have some hints as to why it ran long, and be able to say how often it has been running that way in recent history. A long duration doing very little work was waiting on something else, and other monitoring will help solve that problem. A lot of CPU, reads, or writes shows that you may need to look into tuning or statistics. Just keep in mind that reads can be reads of work tables, and writes can be writes to tempdb.
If you do it right you should have 4 or more days worth of history, and by doing it right I mean having 5 to 10 rollover files sized a reasonable size you can send off if needed (100 MB at most, they zip well) and capturing over the best duration threshold for your environment.
Wait Stats – What’s slowing you down?
The traces tell you what work was done, and the waist statistics tell you what went on when the query couldn’t actively do its work. This is cumulative over the server, so you can’t get details down to an individual process, however, you can see how much time is wasted and where it’s wasted at.
There are almost 500 distinct wait types in 2008 R2, but you don’t need to worry about that. The important thing is to know what are your biggest waits are, and you can look them up if you don’t recognize them. In the last slide I have links to a free eBook written by Jonathan Kehayias and Tom Kruger for the Accidental DBA that does an amazing job documenting what you can ignore and the meaning of the big ones you’re most likely to see.
If you’re looking for overall server health then you would want to look at waits over a long period of time, specifically the times of day you’d like to see better performance. For incidents, you want to look at what your wait stats are now and compare them to your running baseline. For me, the typical baseline I use is the same timeframe yesterday and 7 days ago. These are actual relevant days that have all but the changes you put in over the last couple of days, and it’s a true baseline for this specific server. If this server never waits on PageIOLatch, but it’s in your top 3 today then you instantly have a direction your heading in troubleshooting.
Blocking – Who’s in your way?
Locking occurs when one query is using data, and blocking occurs when another query needs to do something that is incompatible with that lock. If you don’t keep an eye on it then you’re looking back at a trace and seeing that a query took 1 second of CPU, did 1,000 reads, and no writes, yet it figured out a way to take 5 minutes in duration. The users complain the app is slow or unusable, and you’re giving them the answer that you’ll try to figure it out next time it happens and THEN try to find out the root cause.
That’s a bad idea. There are three types of users – those who don’t know you because things are running smooth, those that like you because you can say “I see exactly what happened and I can start working on avoiding reoccurrences”, and those users that you keep telling that you’re not sure what happened and you’ll try to get a better idea the next time it happens. I wish I could tell you that I could have more users not know your name, but watching blocking is a very easy way to get the users that like you to outnumber the users that hate you.
So, what can you do to tell them you know what just happened? My answer is to capture everything that’s blocking on the server every minute. Sure, there’s going to be a lot you capture that is actually only blocking for 10ms, and there are going to be things that were blocking for 59 seconds that were timed perfectly so you never saw it happen. The trick is to know that there is no perfect solution, and capture what you can. The DMVs are there to provide all the information, and being able to capture that on the fly along with in a proactive monitoring setup will make you look amazing to the users. If something blocked for 5 minutes, you have no excuse not to say “This query blocked this query, and this was the head blocker”. Sure you may have an excuse to say “It’s a vendor database and I passed it on to their support”, but at least you can tell the users something, which is always better than nothing.
Query Stats
The DMV dm_exec_query_stats is used by many DBAs, even if all we realized was that we were running one of the “Top 10 Most Expensive Query” scripts off the internet. The problem is that this is using it wrong. This DMV holds everything from when the query first went into cache and loses that information when the query goes out of the cache, even just for being recompiled. So the big process you ran overnight could still be in cache, leading you down a path that’s actually low priority for you. However, that relatively large process that runs every 5 minutes that just recompiled a couple minutes ago due to stats auto updating, it’s not even in there. This is too volatile to say that you’re getting good numbers out of it.
The answer isn’t to find somewhere else to get this information, it’s to capture this information more often and more intelligently. Capture it once and you have a snapshot of what it looked like, capture it again an hour later and you know what work has been done in that hour. Repeat the process over and over again, constantly adding another hour’s worth of data and saving off the latest snapshot in the process and you have some real information to go off of. This isn’t so much of what happened to be in cache at the time, it’s a pretty good summary of what ran and when it ran. Now you can query in detail, specifically saying “I want to know what queries are doing the most physical reads between 9:00 AM and 5:00 PM on weekdays so I can have the biggest impact when I tune this database.”
Index Stats
The DMV dm_exec_index_usage_stats isn’t too different from dm_exec_query_stats except that it’s cumulative since the time SQL services were started. Looking at a snapshot still leaves you half blind, unable to see what happened before the last time you rebooted the server and unable to tell when that index was used. Personally, seeing when it was used is less important to me than how much it was used long-term. Tracking this can do amazing things for you if you’re really fine-tuning a database.
This DMV is really under-used in my experience. As time goes on with a database the data changes and you add more indexes to make it run faster, but you don’t know if or when the index it used to use was being used by anything else so it stays there. Over time that means you have more and more unused indexes, and there’s no solid proof that they aren’t being used without you doing the work to collect that proof. This, in addition to duplicated indexes, adds to the workload for inserts and updates, adds to the workload of index maintenance, adds to the database size, and put additional strain on your cache and thus the PLE.
OS Performance Counters
This is one of the most misunderstood DMVs while also being one of the most useful. It’s giving you critical counters that give you an idea of how SQL Server is interacting with the hardware, but it’s doing it with several different types of counters that have to be measured differently. There are a couple great posts out on the internet to understanding how each one needs to be measured. As for right now, we’re focusing on why you want to watch it and what it will do for you. And wouldn’t you know that I saved the hardest one to describe for last, because each value is different and there will be controversy on which ones you should be watching and which ones are just a waste of your time monitoring.
PLE is one that this is no controversy about if you should watch it. This is the average age of the pages in cache, and a good measurement of when you’re doing too many physical reads. Peeking in on this from time to time is good, you can make sure it’s high enough. However, watching this will let you know when it’s dropping and help you dive into why it’s dropping. If you’re also running a trace you can see what did a lot of reads in that timeframe, and if you’re capturing Query Stats then you can find out which one of your large read queries is doing all the physical reads that destroy your PLE.
Server Target and Total memory are also great to watch even though they rarely change after the server is back up to speed following a restart of SQL services. The target memory is how much SQL Server would like to have, and Total memory is how much it actually does have. If target memory drops then there’s OS pressure you need to worry about. Also, as Total memory is increasing then it means the server is still filling the cache and PLE can pretty much be ignored. Of course it’s low, everything in there is new.
Page Lookups, Page Reads, Page Writes and Lazy Writes give you a better idea of how SQL Server is interacting with your cache and disks. If you want a real picture of what SQL Server is doing behind the scenes, this is much more useful than glancing at cache hit ratio.
Deadlocks and Memory Grants Pending are two things you’d like to always see at zero. That may be out of the question with deadlocks, but if you’re getting above zero on memory grants than you need to find out when that happened and everything that was running at that time.
SQL Compilations and Recompilations are hidden CPU hogs. They’re never going to be at zero because very few servers have stuff stay in cache forever, ad-hoc code runs, and several other reasons. However, when one of these counters jump up, you may have a hidden cause. For instance, if a piece of code that runs every minute or more was written in a way that it can’t be stored in cache, these numbers will be noticeably higher. When this happens, your CPU will be noticeably more stressed with no other indicators as to why, and this query won’t even show up in your Query Stats as it relies on showing the stats of everything that’s currently in cache.
Database Sizes
This seems simple, and it is. Most people know how to find the sizes of their databases, but do you track it? If not, you should. Some questions you should be able to answer readily are how fast your databases are growing, when will you run out of space, and is the steady decline in PLE justified by the growth of the database. Getting into more details, you can touch on when does the database grow such as an accounting app jumping in size every April, or answering if the data is growing steadily or exponentially. These are important things to know when it comes time to budget for new servers and disk space.
On the other side of things, you also have information to push back on application teams on how much space they’re using and if that’s really necessary. A lot of times you’ll find that they’re surprised by their growth to the point that you have to show them the numbers for them to believe it. It’s not uncommon for the response from this to be a cleanup project that helps keep the databases smaller and running faster, which is a big goal being accomplished.
Table Sizes
This is just building off of watching your database sizes in more detail. When a database starts filling up, and it’s filling up quick, it’s good to tell an application team what table is doing it. In my current environment it makes sense to watch every table that is over .5% of the database size AND over 100 MB. This means that some databases we don’t watch anything and other databases we watch about the 20 biggest tables. The biggest point is that we’re not trying to watch everything while watching anything big enough to make a difference to us.
If a database is filling a lot faster than normal then a lot of the time there’s a process that isn’t running like it should. The biggest table in the database may be a rather static value, but the third biggest table in the database wasn’t even on your radar two weeks ago. The app teams love it when you can tell them that not only is the database growing out of control, but we also see the growth in table X which has been growing at 200 MB per day starting on the first Saturday of last month. By the way, wasn’t last Saturday the day you changed a couple procs around or implemented an upgrade?
Now you just graduated from “Hey, there’s a problem” to also include “and here’s a huge lead to finding the root cause.” It’s rare to use this information, but it’s lightweight to capture for something that gives you a heavyweight appearance when you reference this knowledge to other teams.
My Critiques
I’d love to hear what you think about this presentation. Before we get to that, here are the complaints from the most harsh person in the room when I was presenting…
I didn’t do enough to say what each thing was. Although I marked the presentation as intermediate, you don’t know who’s going to be there. In this case, I knew a couple people in the crowd, and they ranged from data analyst to database manager. It should have been presented in more of “If you’re not ready for intermediate then you have everything you need, but it will take some effort to keep up”.
My slides were lacking. I stick with the idea that there should be few words on the screen, but I took it too far. I admitted above that the slides were there more to keep me on track then it was to help the audience, which I probably needed for my first public speaking venue. However, next time I’ll be less nervous and more prepared to make it geared for the audience better. Instead of random pictures, I should have more of graphs and data that I can talk through to give the audience visuals.
Nothing was given to the audience, and there should have been something. To be fair, none of the presentations that I know of handed anything to the audience. However, I set my own bar, and I feel that people would like a sheet of paper with the outline on it with links to online sources. My blog, of course, because it shows how to grab everything. Also, an outside link for each item. This gives a physical reminder to turn this knowledge into action.
There was no demo, and that was the audience’s biggest complaint. While I’m still not sure that I would do a live demo on my second go around, I’m going to hold myself on the remark above about my slides having graphs and data. That would also drag me away from the podium to talk through the slides, making it a more dynamic and interesting presentation; that would really help the audience take things in.
Your Turn
Now I need you to do two things. Put this information to work in your environment is what will help you the most. What will help me the most is you commenting on this post both before and after you implement any of this so you can help me become a better presenter.
Thank you for taking the time to read this!