What do I care about when I’m playing with indexes? That’s easy. I want as few indexes as possible efficiently referenced by as many pertinent, well-tuned, consistently written queries as is reasonable. It’s explaining that last sentence that’s the hard part.
The thing that will jump out to most people is that my goal doesn’t mention a specific, single query that you want to run great. Although that’s something I hope to achieve, it only becomes a priority as a last resort. I’m more concerned with already having that data in memory because the index is being used by many queries, and also having fewer indexes to make data modifications more efficient. There’s more to it than that, but the detail belongs in the body of this post, not the intro.
If I was writing how to make a perfect index for a single reference to a table in a single query, this post could be done rather well in a couple paragraphs. Even though I’m focusing only on OLTP (ruling out columnstore indexes), in 99.999% of environments (ruling out in-memory hash indexes), and not getting into details of filtered indexes or indexed views, there’s still a lot to consider to the point that the first few paragraphs will just be what we’re going to keep in mind. I hope you didn’t have other plans today…
Does this advice apply to you?
It depends! Just kidding, I hate that (non) answer.
There are two targets audiences for this. While it’s useful to everyone, you’d have to hit both of them for this to be perfect for you. First target is the person; this is written for someone who is comfortable working with indexes for single queries but wants a better view of the big picture. Second target is the database, which is a rather typical in-house OLTP database.
- More data than you have memory
- Writes throughout the day, especially in your larger tables
- Read and write performance matter more than disk space
- No extreme write loads, such as truncating and repopulating your largest table (easy fix, disable and rebuild your indexes around this action)
- You have the ability to make indexing changes (this goes beyond what you can typically do with vendor databases)
- Hopefully, you have the ability to make some code changes
If you or your database aren’t the perfect audience, don’t worry about it. The most important things to know are what to keep in mind and how those things are interconnected. The real goal is making more intelligent decisions for your databases, not fitting into a specific mold.
PreReqs!!!
Because this is an advanced look at the fundamentals of indexing strategy, you shouldn’t take offense if you have to do some prerequisite work for all of this to come together. If I give you a severe headache consider reading this stuff first, and the book on the list is well worth a second read cover-to-cover.
PreReqs:
Even with that I’ll probably still give you a headache (a common theme for me), and you’ll probably have questions. Keep in mind that some of the greatest compliments you can give someone are asking them a question and offering them large sums of cash. Although I don’t hand out my LLC’s address to send checks to unless I’ve actually looked over your indexes, I do have a free comments section below that I’d like to see used more often.
Something to consider
Here are all the things we’ll be considering. This is a great list, but nothing is ever going to be 100% all-inclusive or perfect.
Tune your queries: The ideal set of indexes for a poorly written query may be 100% different than the same query after it’s refactored. We don’t want to constantly tinker with indexes, so this process is best if you tune your most expensive queries first. An old, unpublished concept for this post had creating an index as a 13 step process with steps 1-11 avoiding indexes through tuning, step 12 making an index, and step 13 seeing if you could delete any other indexes. That really wasn’t too different from Brent Ozar’s (b|t) Be Creepy method. Indexing is not the only answer, and not the first answer either.
Query Importance: Some queries just need to complete, some need to run decently well, and some need to run as close to instantly as possible. Knowing how critical your query is will weigh in on how you index, but none of them, not even the most critical queries, will have their performance be the only deciding factor on what indexes you should have. Some outliers will require you to go back and create a specific index for them as a last resort, but there’s no reason to concern ourselves with last resorts before we get started. If an index would work, even somewhat inefficiently, and it’ll already be in cache, do we want to create another index that will fight it for space in cache? Don’t create another index to get your most critical query to 0.1 seconds when it’s running at 0.2 seconds and the business is happy with anything under 1.0 second.
Query Consistency: Are you querying the table the same way in all of your queries? If not, do you know you are stressing me out? Do you not care? Using the same columns to join where possible matters, even if you could live without one of them in some cases because consistent queries mean index reusability.
Query Frequency: Some queries run five times a second, some run once a year. They aren’t even close to the same, and shouldn’t be treated the same.
Query Timing: It is different from frequency. Once-a-day is not just once-a-day. An “8-5 is critical” shop where all your users are sleeping at 3 AM means that we care much less about collateral damage from a 3 AM query. If we do a table scan on a huge clustered index at 3 AM that kicks everything out of cache it might not matter much, but do that same thing at 3 PM and we may want to consider an index even if it’s only used for a single query.
Query Justification: That query timing example threw up a red flag to me. Do we need to run that query at all? Does it need to run in prod, or is there a reporting database I can run it against? Should I consider making a reporting database? Does it need to run at 3 PM? Question the outliers that would change your indexing strategy for both if they need to run and if they could use a little T-SQL help.
Insert / Update / Delete performance: The more indexes you have, the slower your data modifications will be because they have to be written more than once. Wider indexes will be more overhead due to updates hitting it more often, larger index to maintain, and fewer rows per page of data.
Reusability: How many queries can use this index, and how will each of them use it? Is a query using it differently because it’s not referencing the table consistently or because it’s legitimately doing something different? This part is HUGE, and is really going to be a major focus. I didn’t give you a hard time on that query consistency point asking if you cared for no reason!
Memory usage: How much memory is being used, where is it being used, and why? Is that memory being used to fulfill multiple queries (see Reusability, which references Query Consistency, which goes back to Query Tuning)? Could we use less memory if we had a descent index? Is the query that requires all that memory justified and timed properly? These points are starting to mix together and reference themselves, aren’t they? Is indexing strategy an infinite loop?!?!? Yes, yes it is.
Key Lookups: For the queries that use this index, is this a covering index? If not, what would it need to be a covering index? We’ll look at these things: how critical is each query, how often is that query run, how many key lookups does it do, how wide are the total columns we would need to add to be covering, how often are each of those columns updated, what other queries would take advantage of having those columns in there, and is there any filtering being done on those columns?
Maintenance: It’s easy to see having fewer, more narrow indexes would make index rebuilds, index reorgs, and database backups quicker and easier. How about key column order and compression?
TDE: What’s this feature doing in an indexing article?
SQL Edition: Index compression is going to be the biggest one for us today. Online rebuilds can make a big difference, too, but it rarely makes a big difference in what indexes you want.
Pick a table, any table
We’re not going to change the entire database at once. Partially because it’s overwhelming to you, but mostly because it’s lower risk that’s easier to troubleshoot and roll back if needed. So we’ll pick a single table that we want to have run more efficiently, make a change or two to it, then do it again with either the same table or a different one.
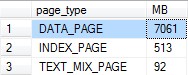
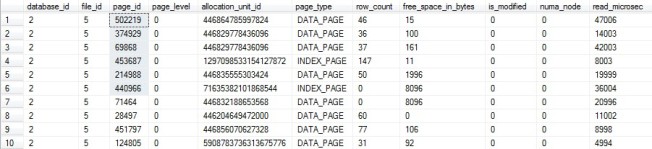
I’m not consistent on how I pick tables. Although I usually pick one of the ones that’s the largest in the buffer pool that I haven’t made as efficient as I could already, which you can find using the query in my Cleaning Up the Buffer Pool post. However, that’s not always how I pick a table. I’ll also start this off with a query that I wish was running faster, run it with SET STATISTICS IO, TIME ON to see what tables are getting hit in the slowest part, and work on a table that’s getting hit inefficiently here. There’s no magic to it, just pick a table and reassure the other tables that they’ll get their turn later.
It looks like an infinite loop at first glance because I’ll keep picking tables and loop back to revisit table later, but it’s better to think of it as an upward spiral. That first trip around will give you all kinds of awesome, the second trip will add on to that, and each trip around yields less of an improvement. You could stop wherever you wanted if it wasn’t addictive.
Also as the size of your data changes, the queries hitting your database change, and more, it’s unreasonable to expect your indexing strategy to stay 100% the same. This isn’t a job where you can ever say you’re really done, just in a better place than you were last week.
I have a table, now what?
At the times of day you want your database to perform great, what’s happening with your table? This may be anything that ever runs on the database for some places, and it may be anything that runs between 8 AM and 5 PM for others.
I’m being as all inclusive as possible by looking at everything that touches the table, so this won’t be as quick and easy as you’d think. Yes, my target audience for this post can create an index for a single query in minutes while I typically spend well over an hour on a single table; how fast you make it through this project isn’t my primary concern.
Once you picked a table to work on look in the proc cache to see what references the indexes on the table. My query to do that in the same Cleaning Up the Buffer Pool post is good for this, but the one in Querying the Plan Cache is better for viewing an entire table at once. This has every cacheable plan that ran since the last restart of services and hasn’t been forced out of memory. Remember this is a really CPU intensive query that will take several minutes to run and needs to run against prod at a time of day you care about to provide what you need. If you have an extremely busy hour or two, run this as soon as things start to calm down.
Note, there were three different ways something could have avoided you seeing it in the proc cache, and that wasn’t counting if you turned on the typically recommended setting “Optimize for ad-hoc workload” that Kimberly Tripp (b|t) wrote about where you can miss the first run of ad-hoc queries in favor of keeping your memory cleaner. It’s also possible that a query is getting a different plan each time it gets compiled due to stats changing or parameter sniffing, but that affects us a little less since we’re going to make index changes that will change those plans anyways.
The proc cache query is also only capturing index usage. It does capture RID lookups, but not table scans against a heap. You’ll have to look at the modified scripts I put in Querying the Plan Cache to see the table scans because they’re stored differently in the XML.
For now, let’s focus on how things can sneak past our cache and how we can find them.
1 & 2: Was not run since the last restart of services or was forced out of memory. It can be in cache, it’s just not there right now. For that, we’re going to check back on the cache multiple times, and we’re also going to make one or two index changes at a time which will again have us checking back multiple times.
3: Uncacheable plans can happen for several reasons, with the most popular in my experience being temp tables where data was loaded into it then an index was created on the temp table. Whatever the reason, start up extended events or a trace and watch for sql_statement_recompile to help hunt them down. Take this list and search for references of your table to know which ones are relevant. To get bonus points (I’m not keeping score), find out why it’s not getting along with your cache and see if it’s something that should be fixed.
To make things a little more difficult in that step, you’ll also have to look for references to views and functions that reference the table. The views and functions will show up in my Proc Contains Text query, and you’ll have to iterate through that process again.
Keep in mind, this will never be perfect and 100% all-inclusive. I know I said that before, but I need some of the important details repeated to me before they sink in and I have to assume there are others like me. It will be very rare for this to pick up an ad-hoc query that runs for year-end processing. You can use your imagination to find 10 other ways you’ll miss something and still be shocked when a new way pops up.
However, we have enough to move forward, and we’re going to accept the rest as acceptable risk. If you don’t accept some risk you’ll never accept any rewards, it’s just a matter of reducing the risk and knowing enough to make an intelligent decision.
Now that you know what’s running, how is each one referencing the table? Looking at the proc cache, you’ll see predicates and seek predicates, which you’ll combine on a list. You’re going to have to run the stuff that didn’t make it into the proc cache manually on a test server and add them to the list as well.
This is completely overwhelming to do all of it. The more you do, the more accurate your results will be, but it’s not actually reasonable. Do what’s reasonable, understand that you’re trading off some level of accuracy for time, and also understand that if you don’t make that tradeoff then you’ll never have time for anything else…not even going home at night.
Here’s what the list could use:
- Proc or name of SQL Batch
- How important is it
- How often does it run
- When does it run
- Predicates and Seek Predicates (let’s just call them predicates)
- Equality columns
- Range columns
- Inequality columns
- Column’s returned
- Rows returned
If there was a RID or Key Lookup on a reference to a nonclustered index, add the output columns and predicate (not the seek predicate for this case only) from the lookup on here as well. The seek predicate on a lookup is just the clustered index key or RID bookmark added as hidden key columns on your nonclustered index; they will not help you here.
Now look at this list and look for consistencies. What equality predicates are used a lot? You should be able to find different groups of equality predicates that can accommodate most of your queries, and those are going to be the key columns you’ll consider for your indexes. The first key column is going to be the column all of the queries you want to use this index have in common as an equality column, then iterate through them as the columns are used less and less.
This is not the traditional “order of cardinality” advice I’m sure you’ve heard when creating an index for a specific query, but we’re designing an index for your database, not your query. I’ll go one step further and say if it’s a toss-up between what’s the first key column, consider making it one that’s added sequentially such as DateAdded or ID on tables that see more updates because that will reduce page splits and fragmentation.
A query can take advantage of the chain of key columns starting with the first one. The chain can continue after each equality use. An inequality or range can take advantage of a key column as well, but the first one of these is the end of your chain. Once the chain is broken, everything else can be useful, but only as unordered values that don’t matter if they’re key columns or included columns.
You can stop putting in key columns when either queries stop being able to take advantage of them being ordered or the values you’re getting are either unique or close enough. These key columns aren’t free as Paul Randal (b|t) points out in his post On index key size, index depth, and performance. If a key column is not very useful, then it’s very useful not to have it there.
I should note that if you’re using an index to enforce uniqueness then it will use all the key columns and none of the included columns to do so. Based on the last paragraph you don’t want any key columns after it’s unique anyways, so don’t even consider that. However, included columns aren’t used to calculate uniqueness, so you can make this a covering index if it helps you without hurting the unique constraint.
This process, like any other indexing process, isn’t going to be perfect. You’ll have to weigh your decisions with queries that are more critical or are called more often carry more weight in your decision.
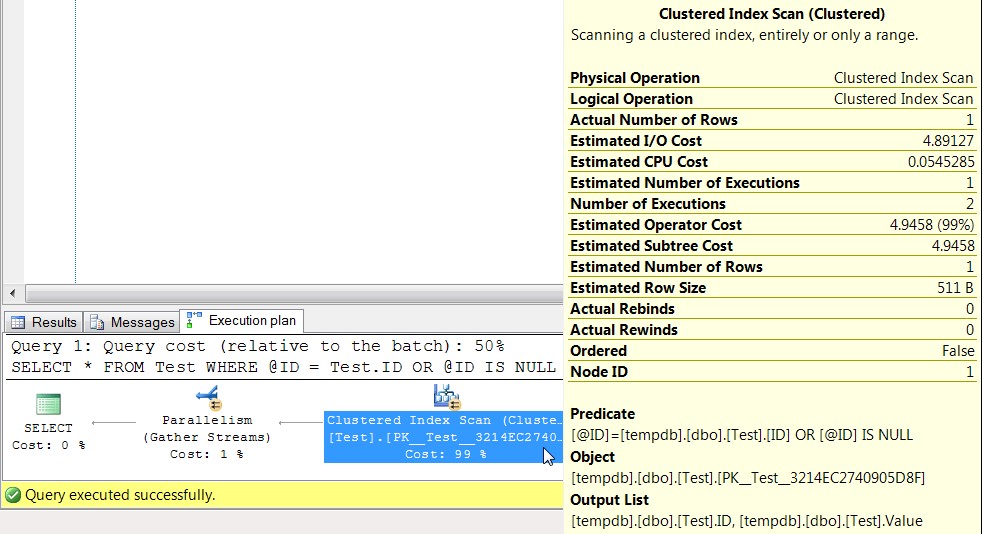
Now that you have your key columns figured out, look at the queries that use more than just those columns. When they reference this index how many rows are they going to return where they have to get more information from the table itself through a lookup? How wide are those columns, and how many other queries are going to do the same? This is the balancing act between adding included columns and accepting key lookups. A key lookup is going to be a nested loop operation making separate calls to get the missing columns from the clustered index (or heap, for those who wish to anger me), so 10,000 key lookups is 10,000 separate calls in a loop. If you have to add a large number of columns to eliminate 10 key lookups then it’s almost never worth it. If you have to add one small column to eliminate 1,000,000 key lookups then it’s almost always worth it. Notice I didn’t use determinate language on those…you’ll have to find your balance, test it, and balance it again.
Some things like adding a column to avoid key lookups may make more of a difference to you than the user, but that doesn’t make it less important. For instance, I just said adding a small column to eliminate 1,000,000 key lookups is almost always worth it. If those 1,000,000 key lookups were from a single execution of a query then the user would probably notice, they might even buy you lunch if you’re lucky. If it was a single key lookup on a query run 1,000,000 times that day it’s still a drop in CPU utilization and a potential 1,000,000 pages from the clustered index that didn’t have to be read into cache. You’re doing this because it adds up to a better running server, not always because it’s noticed.
Your goal here is making an index as reusable as is reasonable. Here are the reasons you’re doing that:
- Every index will fight to be in cache (assuming you don’t have vastly more memory than databases to fill it), an index that is reusable by many queries will be more likely to already be in cache and that space in cache will be more versatile.
- Every index is another write process in an Insert, Update, and Delete, you’re trying to cut down on those.
- Every index needs to be maintained, you’re cutting down on that, too.
- Every index adds disk space, backup size, backup duration, restore durations, etc..
- If you use TDE, every time a page is read from disk into memory it is decrypted. A reusable index tends to stay in memory more, reducing the number of times the CPU has to decrypt it. See, I TOLD you this belonged in an indexing strategy post!
Nothing’s free, so here’s what you’re giving up:
- The index isn’t going to be the prefect index for most queries. Test the performance of your critical queries, but also keep in mind that these indexes are more likely to be in cache which could eliminate physical reads from the execution of those queries.
- These indexes will tend to be wider than the query needs, which is basically restating that this isn’t going to be the perfect, most efficient index for a query. It also means that physical reads on these indexes will tend to be more expensive as there are fewer rows per page. Again, keep in mind they’re more likely to be in memory because you’re going with fewer indexes that are shared by more queries.
Once you decide on an index or two to add, there are a couple things to consider.
- What indexes don’t you want anymore? If a query could use another index slightly more efficiently, it will. However, if it’s close enough then you want to get rid of that other index because of all those benefits of reusability I just mentioned (weren’t you paying attention?). It’s not a question of if a query would use the other index, it’s a question of if you want it to use it.
- Some queries “should” use this index based on the key columns, but instead of it showing up as a seek predicate it shows up as a predicate. In these cases either your chain of key columns was broken (if column 2 wasn’t an equality column, column 3 will not be a seek predicate) or this column is not being referenced in a SARGable way.
- Test in non-prod, not prod. Then test it again.
- Know you’re accepting risk and understand everything involved the best you can. Have a healthy fear of that risk while also understanding that you took a risk just driving to work this morning.
Once these changes go through keep an eye on how they’re being used over the next couple weeks. If you’re in a rush to make a big impact, start a second table as the first change or two are in progress on the first table. Just don’t get too many changes in motion for a single table at once as that’s typically adding more risk and hiding which changes had positive and negative impacts. This is a process, and the longer it takes you do go through it the better the chance is that you’re doing it right.
If I’m doing this process for someone else who wants consistent improvement without taking on too much time or risk at once, then I like to get on their servers once or twice a month, find one or two changes to suggest, then have those go through testing and implementation. Afterwards review the results and come up with the next suggestion. It’s hard to be that patient as a full-time employee, but try.
Cluster It
All of that was talking about nonclustered indexes, but you get to pick a clustered index for your table as well. Keep in mind this is a bigger change and involves more risk, but it’s also a bigger reward.
So, what do I care about that’s special for a clustered index?
- Uniqueness
- Key width
- Width of columns being queried
- Column types being returned (some can’t be in nonclustered indexes)
- Number of rows being returned
The size of your key columns on your clustered index is the MINIMUM size of the key columns on a nonunique nonclustered index, and it’s also the MINIMUM width of the page level of any nonclustered index. You need to keep that in mind.
However, just because your table has an identity column in it doesn’t mean that’s the best clustered index. What is the best clustered index is going to vary wildly from table to table; there’s not always going to be a clear answer, and the answer will partially depend on how the table is queried. I get into that a lot more in my last post, Picking a Clustered Index. Yes, I wrote that post specifically to keep this one shorter…with mixed results.
If a table is often queried by a relatively small column that’s not unique, but the queries tend to pull back most of the columns in the table and a large number of rows then it’s worth considering using this as part of the clustered index key.
If you don’t then you’re faced with two solutions; you can make a really wide nonclustered index to cover these queries, or you can let the queries decide if they want to do a ton of key lookups or just scan the clustered index. These don’t sound like fun to me.
You still have to worry about the integrity of your data, so if you’re dropping the unique clustered index with a single column to do this then you almost definitely want to add a unique nonclustered index with that single key column to maintain your data integrity.
Compress It
Index compression is an Enterprise-ONLY feature.
Compression is a very big point to hit on here, even if I’m only giving you the compressed version. It makes your data smaller on disk (less I/O), smaller in memory (less need for I/O), and actually tends to lower your CPU usage instead of raising it. I get into a lot more detail in my Data Compression post because I didn’t want to have too much space dedicated to a feature not everyone can use here.
Don’t Forget the Outliers
Go back to that list you made of all the queries hitting a specific table. Were some of the queries different than the rest? There are usually a couple, and that doesn’t necessarily mean there’s an issue. However, I look at these to determine if they are using the table properly.
Are they are joining on all the fields they should be. Sometimes you can get the correct results by joining on 3 of the 4 fields you technically should, so why join on the 4th? Well, index reusability is one of those reasons, because it may not be able to use the proper index because someone skipped a column that happens to be the first key field of the perfect index for this query.
Is the query SARGable? Sometimes you’re joining or filtering on the right fields, but something is written in a way that SQL couldn’t do a direct comparison.
Are you returning too many columns? I’ve seen queries returning 20 columns (or using *, which is a move obvious version of the same thing) to populate a screen that uses 3 of them, and on the SQL side you have a DBA trying to figure out if they should add included columns to an index to make that run more efficiently. The most efficient for this and many other examples is refactoring, not reindexing.
Remember, your goal is to make your server run more efficiently, and tweaking indexes is simply one of your tools. While you’re going through this process keep your eyes open towards how other tools can be used. SSMS is never going to come up with a warning telling you that you should read a book or two by Itzik Ben-Gan (b|t) or Kalen Delaney (b|t), but I would welcome that change.
Does this negate my previous advice?
If you follow my blog at all, which is suggested in my very biased opinion, you may have seen me talk about Unused and Duplicate Indexes, but I make no mention of them here. Did I forget about them?
No, I did not. This is designing every index you want to have on your table in a reusable way. If that index was not on the list then you’ll want to consider getting rid of it. It’s two ways of looking at the same thing. A complete understanding of both of these methods will help you make intelligent indexing decisions and go as far as you need to for the situation you’re in.
Talk to me
This isn’t a short or easy process, and perhaps I could have worded some of it better. I enjoy what I do, both writing this post and playing with indexes, and having someone think enough of me to ask me questions on this makes it all the more enjoyable.
I may be rewriting parts of this post as I find ways to reword concepts better, especially as I finalize and tweak my presentation with the same name for which this post is my guide. That presentation will make its debut at SQL Saturday Cleveland on February 6, 2016.
If you feel you can help me improve, please don’t hold back. I’d rather feel that I’m improving than falsely believe I’m infallible.